April 12, 2026: The AI Awakening—Memory, Experts, and Smart Agents
AI is evolving from forgetful stateless systems to context-aware agents. Explore memory layers, hyper-efficient MoE models, and precise retrieval that will transform enterprise AI.

Today's Key AI Stories
- AI Memory Systems: Why coding assistants need context layers to stop forgetting.
- MiniMax M2.7 Launch: A 230B MoE model making agentic workflows hyper-efficient on NVIDIA.
- Advanced RAG: How cross-encoders and reranking are solving data retrieval accuracy.
- Unity & Reinforcement Learning: Teaching AI to learn through trial and error in game engines.
The Great AI Shift: From Stateless to Context-Aware
AI is incredibly smart. Yet, it is deeply flawed. It suffers from a fatal disease. It has digital amnesia.
Think about it. Every time you open a new chat. Every time you ask a question. The AI starts from zero. It does not know you. It does not remember yesterday.
You are a stranger to it. Every single time.
This is the core problem of Large Language Models (LLMs). They are designed to be stateless. This protects your privacy. But it destroys your productivity.

The Tax of Repetition
You use an AI coding assistant. You ask it to build a dashboard. It uses React. You say, no, I use Streamlit. It uses Plotly. You say, no, I use Altair.
Four prompts later. Ten minutes wasted. You finally get the code you need.
This is a tax. You pay this tax every day. You become the human memory layer. You copy-paste context. You explain the same rules over and over.
This does not scale. It is exhausting. But there is a cure.
Context Engineering is the Future
We are entering the era of Context Engineering. This is bigger than prompt engineering.
Prompt engineering is asking better questions. Context engineering is giving the AI the perfect background. It is like onboarding a new employee. You give them a handbook. You don't make them guess the rules.
There are four levels to this.
Level 1 is explicit memory. You write a rules file. A simple Markdown file. `AGENTS.md` or `CLAUDE.md`. You put it in your project folder. The AI reads it first. It knows your tech stack. It knows your style. Zero repetition.
Level 2 is global rules. These are your personal habits. How you think. How you communicate. They travel with you across all projects.
Level 3 is implicit memory. The AI watches you work. It learns your preferences silently. It runs in the background. It connects the dots.
Level 4 is custom infrastructure. Full vector databases. Retrieval-Augmented Generation. Enterprise-grade memory APIs. Memories that persist forever.
What is the takeaway? Context is a precious resource. Manage it intentionally. Stop repeating yourself. Write the rules once. Watch the returns compound over time.
The Efficiency Engine: Enter MiniMax M2.7
Let us shift gears. We want smarter AI. But smart AI is huge. Huge AI is expensive. Compute is the new oil. And servers cost a fortune.
How do we solve this? We use a brilliant architecture. It is called Mixture-of-Experts (MoE).
Today, MiniMax released the M2.7 model. It is built for complex tasks. Agentic workflows. Coding. Deep reasoning. It is available across the open-source ecosystem. And it runs beautifully on NVIDIA.

The Genius of MoE
Let me explain MoE simply. Imagine a giant hospital.
This hospital has 256 specialist doctors. You walk in with a broken arm. Do you need all 256 doctors to look at you? No. You only need the bone specialist. The X-ray tech. The cast expert.
The hospital is massive. But your specific cost is tiny.
This is exactly how MiniMax M2.7 works. It has a staggering 230 billion parameters in total. But for any single word it generates, it only activates 10 billion parameters.
Its activation rate is just 4.3 percent. It uses 256 local experts. But only 8 experts wake up per token.
What does this mean for business?
It means massive capability at a fraction of the cost. You get the brainpower of a 230B model. But you pay the inference cost of a 10B model. This is the holy grail of AI economics.

Speed Meets Scale
NVIDIA partnered with the open-source community here. They optimized the kernels. They integrated it into vLLM and SGLang. The results are stunning.
Throughput improved by up to 2.7 times on Blackwell Ultra GPUs. It can handle a 200K input context length. That is an entire book of data in one prompt.
This is not just an incremental update. This is a leap. When you reduce the cost of intelligence, you change the world. More companies can afford agents. More tasks get automated. The barrier to entry drops.
The Search for Truth: Advanced RAG and Reranking
Now, let us talk about data. Enterprise AI relies on RAG. Retrieval-Augmented Generation.
You ask the AI a question. The system searches your company data. It finds the answer. It gives it to the AI. The AI writes the response.
It sounds perfect. But there is a catch. Search is often dumb.

The Two-Stage Funnel
When you use a basic bi-encoder, it is like casting a wide fishing net. You catch a lot of fish. But you also catch old boots. You catch seaweed. The AI gets confused. It hallucinates.
We need a better filter. We need a second look.
This is where cross-encoders come in. This is the art of reranking.
Think of the first step as a junior researcher. They run to the library. They grab 50 books that might have the answer. They are fast, but not precise.
Think of the second step as the senior editor. The cross-encoder. The editor reads the specific question. They carefully evaluate all 50 books. They rank them. They pick the top 3 absolute best sources.
Only those 3 perfect sources go to the LLM.
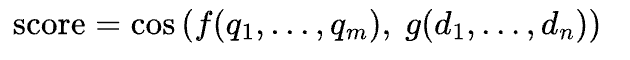
Why Accuracy Matters
Why go through this trouble? Because in business, being mostly right is not enough.
If your customer service bot gives the wrong refund policy, you lose money. If your legal AI cites the wrong case, you lose the lawsuit.
A two-stage retrieval pattern fixes this. You use a bi-encoder for speed. You use a cross-encoder for precision. You get the best of both worlds.
You can even fine-tune these models. You can teach them your specific industry jargon. You can use semantic caching. This speeds up repeated questions. You save compute. You increase trust.
A smart retrieval pipeline is your moat. It is what separates a toy AI from an enterprise engine. Your AI is only as smart as the data you feed it. Feed it well.
Learning by Doing: Unity and Reinforcement Learning
Finally, let us look to the future. How will AI interact with the physical world?
Right now, LLMs predict the next word. They live in text. But what about robots? What about self-driving cars? What about game NPCs?
They cannot just read. They must act. They must learn from the environment.
This is Reinforcement Learning (RL). And it is beautiful.

The Mathematics of Trial and Error
Think of a toddler learning to walk. They stand up. They fall down. Pain. Negative reward. They stand up again. They shift their weight. They take a step. Joy. Positive reward.
This is the exact loop of Reinforcement Learning.
An agent takes an action. The action changes the environment. The agent observes the new state. The agent gets a reward or a punishment. The agent updates its strategy. It tries again.
This is happening right now in the Unity game engine. Developers are training agents in virtual worlds.
It involves deep mathematics. The Bellman Equation. Q-Learning. Deep Q-Networks. But the philosophy is simple: Learn by doing.

Exploration vs. Exploitation
There is a profound concept in RL. It applies to AI, and it applies to life.
It is the tradeoff between exploration and exploitation.
Imagine going out for dinner. Do you go to your favorite restaurant? You know the food is good. You exploit your current knowledge. Or do you try the new place down the street? It might be terrible. But it might be your new favorite. You explore.
AI agents face the exact same dilemma. If they only exploit, they never discover better solutions. If they only explore, they never master a skill.
Using an epsilon-greedy policy, agents balance this perfectly. They explore randomly at first. Slowly, as they learn, they shift to exploiting the best path.
By training these models in Unity, we simulate millions of years of evolution in minutes. Today, it is a game character navigating a maze. Tomorrow, it is a humanoid robot making you breakfast.
The Grand Synthesis: What It All Means
Let us connect the dots. Today’s news paints a clear picture of tomorrow.
First, AI is getting a memory. Context layers ensure that assistants stop forgetting and start compounding value.
Second, AI is getting efficient. MiniMax M2.7 proves that Mixture-of-Experts can deliver massive brainpower without bankrupting server farms.
Third, AI is getting precise. Cross-encoders and advanced RAG ensure that enterprise systems find the exact truth, not just a close guess.
Fourth, AI is learning to act. Reinforcement learning in Unity is building the bridge from text boxes to moving, acting agents.
We are moving from static chatbots to dynamic, affordable, context-aware agents. They will know your history. They will run cheaply. They will retrieve accurate data. And they will act in the world to solve your problems.
This is not just technology. This is leverage. The companies that understand this will move ten times faster. The rest will be left explaining their rules to an amnesic chatbot, over and over again.
The shift is here. Adapt accordingly.